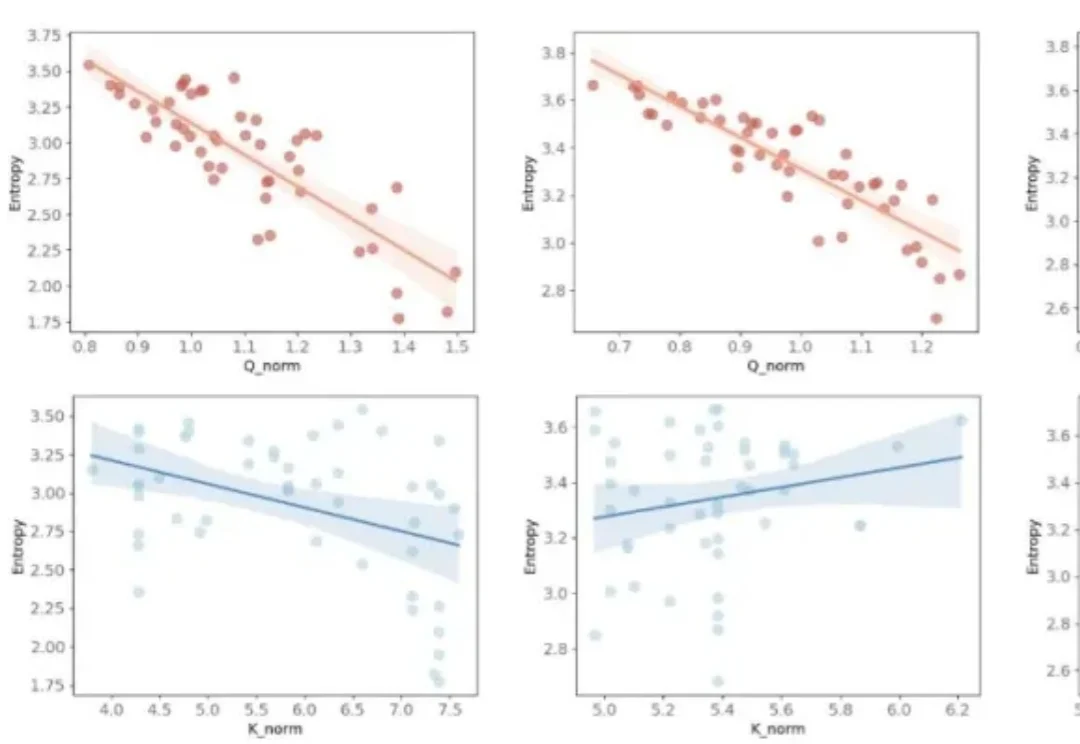
全新线性注意力范式!哈工深张正团队提出模长感知线性注意力!显存直降92.3%!
全新线性注意力范式!哈工深张正团队提出模长感知线性注意力!显存直降92.3%!当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。
来自主题: AI技术研报
5805 点击 2026-03-17 08:48
 搜索
搜索
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”
在十九世纪的暹罗王国曾诞生过这样一对连体兄弟:他们分别拥有完整的四肢和独立的大脑,但他们六十余年的人生被腰部相连着的一段不到十厘米的组织带永远绑定在了一起。他们的连体曾带来无尽的束缚,直到他们离开暹罗,走上马戏团的舞台。十年间,两兄弟以近乎合二为一的默契巡演欧美,获得巨大成功。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。

过去几年,机制可解释性(Mechanistic Interpretability)让研究者得以在 Transformer 这一 “黑盒” 里追踪信息如何流动、表征如何形成:从单个神经元到注意力头,再到跨层电路。但在很多场景里,研究者真正关心的不只是 “模型为什么这么答”,还包括 “能不能更稳、更准、更省,更安全”。
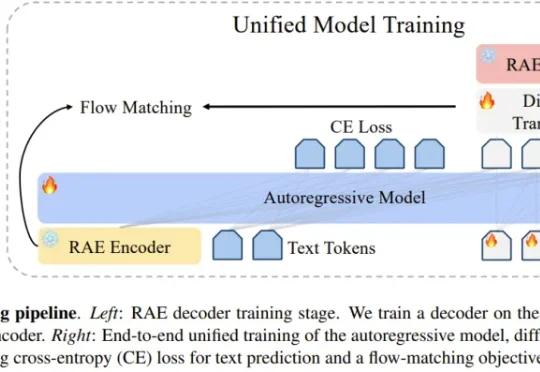
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视

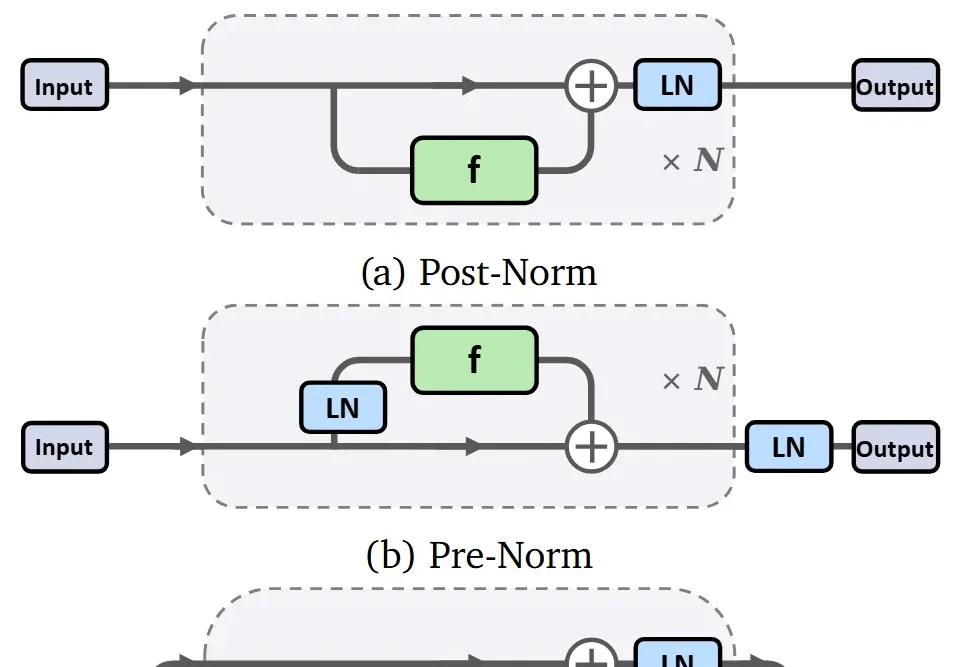
这篇新论文提出了一种非常简单的新激活层 Derf(Dynamic erf),让「无归一化(Normalization-Free)」的 Transformer 不仅能稳定训练,还在多个设置下性能超过了带 LayerNorm 的标准 Transformer。
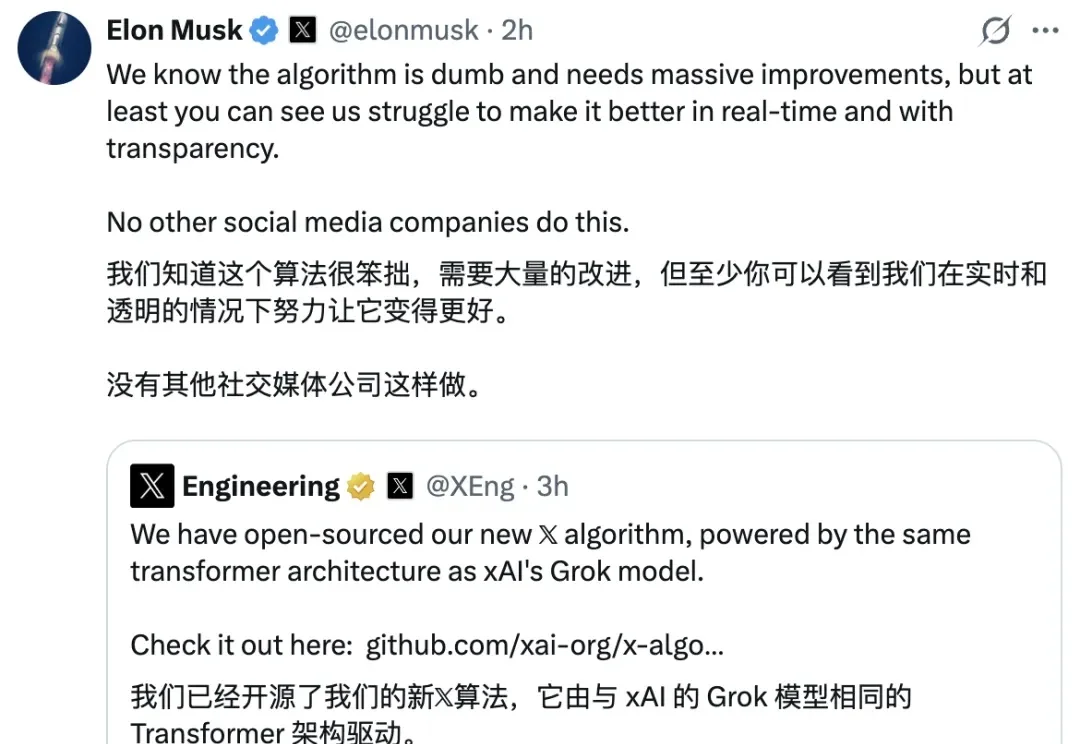
刚刚,𝕏 平台(原 Twitter 平台)公布了全新的开源消息:已将全新的推荐算法开源,该算法由与 xAI 的 Grok 模型相同的 Transformer 架构驱动。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。